Systems
Just like for people, when we can interact our interactions become a part of a system. When an agent (or model) engages in an interaction with another agent, the result is an agent system. The systems can be ordered or disordered, and interact with varying degrees of regulation as imposed by the environment, which includes other agents. To help steer the systems a person may be essential, though fully autonomous systems are of high intriguing for practical and theoretical reasons.
Agent systems are integral components of the next stage of AI
Individual agents are not individually ideal to perform the variety of tasks that are given to them. Prompt-engineering, memories and their derivative personas can enable different quality of output. Working together, different agents have the potential to create more successful outcomes.
The challenge is how?
This is an important question and bridges the gaps between complexity organization and process design.
Frameworks¶
Agentic Systems require that there is communication with and between AI-agents. To produce complexity management and success-potential, they are enabled through frameworks that permit certain forms of interactions. A higher level cognitive architecture that can be built up in various manners to achieve end-goals effectively.
Here are a few frameworks of importance.
LangGraph¶
LangGraph provides a simple interaction diagram to allow custom-built systems of interaction
It is important to consider LangGraph

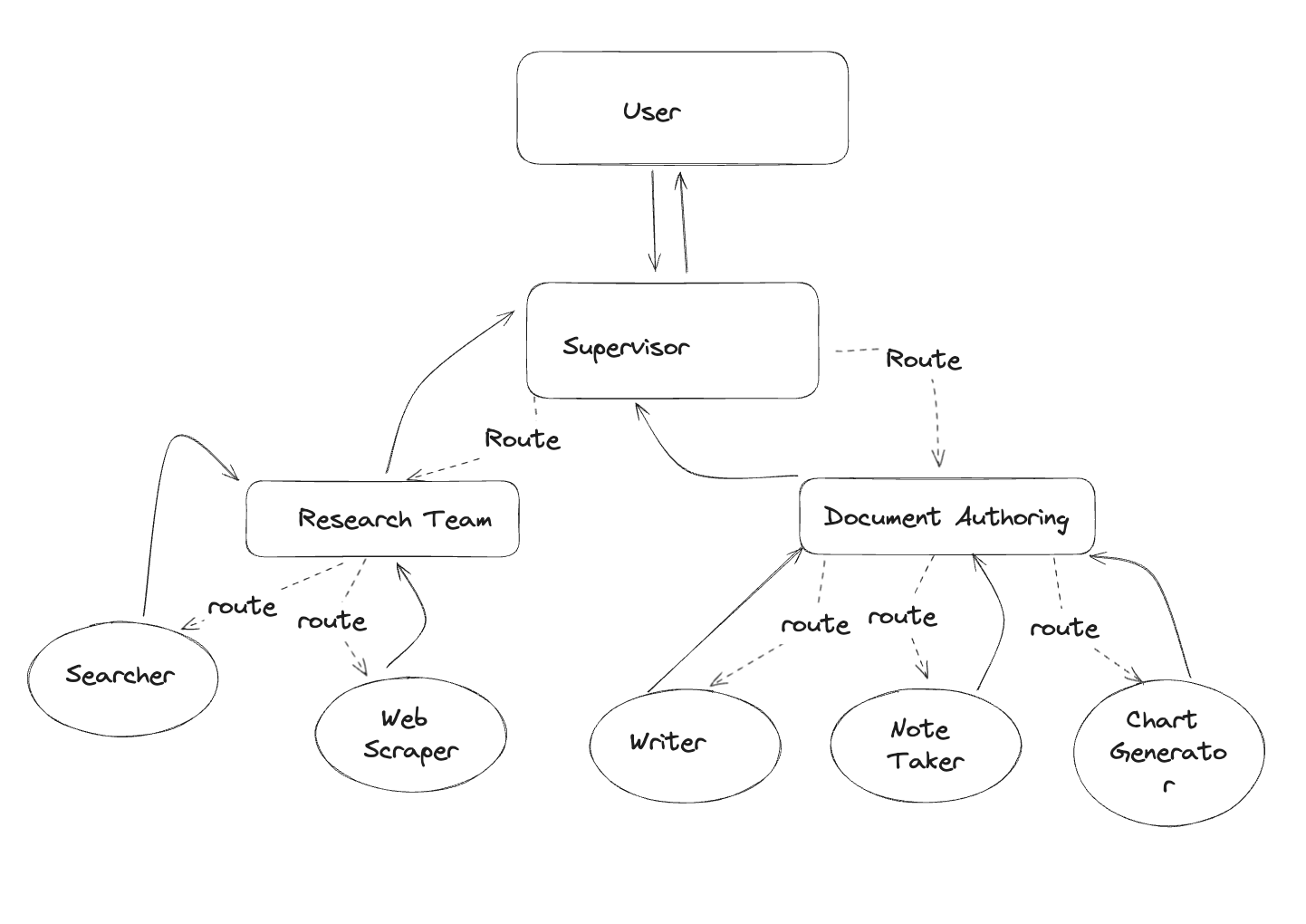
Some examples gpt-newspaper, lang-graph-crewAI
 AutoGen enables LLM application development with communication between multiple agents.
AutoGen enables LLM application development with communication between multiple agents.
Paper
TRY THIS!
 Crew.ai is a framework for
Crew.ai is a framework for
 ChatDev is a communicative agent approach allowing for development of solutions using ML models.
ChatDev is a communicative agent approach allowing for development of solutions using ML models.
Works with Camel to create agentic systems and has some generally good results. It is certainly not full-fledged software but provides a solid framework for creating systems of agents to produce software-enabled products.
 Agency Swarm provides a language creating interacting systems of agents.
Agency Swarm provides a language creating interacting systems of agents.
 MetaGPT enables different agents to interact and generate meaningful outputs based on varying tasks and personas.
MetaGPT enables different agents to interact and generate meaningful outputs based on varying tasks and personas.
'🤖 Assemble, configure, and deploy autonomous AI Agent(s) Reworkd/AgentGPT '🤖 Assemble, configure, and deploy autonomous AI Agent(s) in your browser. 🤖'
This model leverages different game-roles and LLMs to provide feedback on how to optimize the model and facilitate autonomous enhancement during gameplay.
Commercial Examples¶
OpenAI¶
OpenAI released their ability to integrate or call different AI assistants be called within a chat using the @ symbol. Similar to tagging in chat-interfaces, with a human
Theoretical Classifications¶
Binary system (asymmetric calling)
In this system, ChatGPT initiates communication with DallE using a prompt. DallE responds by delivering an image. This image is then used in the final response of ChatGPT or returned as-is.
Multi-body system (bidirectional calling)
This system consists of multiple agents, and they engage in ongoing discussions about their daily activities. They also receive regular updates about their environment. An example of this type of system can be viewed in this paper.
Papers¶
Polaris: A Safety-focused LLM Constellation Architecture for Healthcare
Description The authors reval a LLM agent system to ensure safe and compliant AI chatbots for healthcare
Society of Minds: To Enable Societal Interactions to Improve Output
The foundation of the multi-agent debate approach involves pitting multiple LLM instances against each other, where each proposes and argues a response to a given prompt. Through rounds of exchange, the objective is to collectively review and refine answers, ultimately reaching a well-reviewed, accurate final response.
Also Marvin Minsky YouTube "Society of Mind"
From Medium article…
In his 1986 book The Society of Mind, Minksy, the founder of MIT’s AI laboratory, presented his theory of how the mind works. He proposed that it is not a single entity but rather a complex system composed of many smaller, simpler processes that Minsky called “agents”. These agents, each simple in itself, work together to create intelligent behavior, the behavior that AI is every day trying to imitate from us humans. Now, this fascinating theory has inspired a select group of MIT and Google Brain researchers to present the next breakthrough in Generative AI, a new way to fight the largest enemy of Large Language Models (LLMs) like ChatGPT.
The proposed method works by creating a “society of minds” where multiple instances of a language model propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a single common answer.
Here’s a more detailed breakdown:
- Given a query, multiple instances of a language model (or several ones) first generate individual candidate answers.
- Each individual model instance reads and critiques the responses of all other models and uses this content to update its own answer.
- This step is then repeated over several rounds until we reach a final answer.
This process induces models to construct answers that are consistent with both their internal critic as well as sensible in light of the responses of other agents.
The resulting quorum of models can hold and maintain multiple chains of reasoning and possible answers simultaneously before proposing the final answer.
Experiential Co-Learning of Software-Developing Agents
Introduces a multi-agent paradigm that enables two types of language-agent using three modules of integration:
Co-tracking that 'promotes interactive rehearsals between the agents' enabling joint exploration of procedural trajectories.
-
During this process an instructor provides a set of instruction to which assisstants responds. This is viewed as a directed chain, connecting the node responses to the edge which is a transition-record from nodes \(r_j\) to \(r_{j+1}\) given instructions \(i_{j+1}\), \(E = (r_j, i_{j+1}, r_{j+1})\). The task execution represents the completion process, combining the 'collaborative dynamics between both agents'. TODO: FIX THIS; it isn't quite right
Co-memorizing that looks for shortcuts based on past experiences and the environmental feedback, that allows information to be put into 'collective experience pools'.flowchart LR subgraph instructor["Instructor"] i1["Instruction \( i_{j} \)"] i2["Instruction \( i_{j+1} \)"] end subgraph assistants["Assistants"] r1["Response \( r_{j} \)"] r2["Response \( r_{j+1} \)"] end i1 -->|provides| r1 r1 -->|responds with| i2 i2 -->|provides| r2 r2 -->|responds with| i1 r1 -->|transition-record| r2 -
Nodes sharing the same state are agregated via a embedding hash. These are examiend with a graph-compiler to find shortcuts for task-completion. When done, the co-memorization routine compells the instructor to use the document the routes for better guidance to record the end-points.
- The node feedback can be compared by looking at the product similarity between the node response \(r_j\), the general task, the similarity between that node, and other nodes, and, the compilation success for node \(r_j\).
- This allows for the construction of key-value pairs showing the best states from \(r_i\), with \(r_i \Rightarrow r_j\) and with \(r_i \Rightarrow r_j\) to \(r_j\).
graph TD
subgraph state_pool["Collective Experience Pools"]
A["Embedding Hash Aggregation"]
B["Graph Compiler"]
C["Documentation of Routes"]
end
A -->|examines| B
B -->|finds shortcuts| C
C -->|records endpoints| ACo-reasoning encourages instruction enhancement from their experience pools
- This step combines experience pools to generate refined insights in collaborative problem states, using memories to seed few-shot examples for instructions and responses as in retrieval based prompting
- With a response to instruction memory \(M_I\) encountering the task state \(r_j\), a retrieval tool, acesses experiential instructions matching the meaning of the task to provide zerofew-shot examples. to guide the instructors reasoning to share with the assistant.
- The assistant with an instruction-to-response memory \(M_A\) retrieves optimal responses based on the received instruction, allowing few-shot examples to create the next response.
flowchart LR
subgraph experience_pools["Experience Pools"]
MI["Instruction Memory $$M_I$$ "]
MA["Assistant Memory \( M_A \)"]
end
subgraph reasoning["Instruction Enhancement"]
task_state["Task State \( r_j \)"]
retrieval["Retrieval Tool"]
few_shot["Few-Shot Examples"]
end
task_state -->|encounters| MI
MI -->|accesses| retrieval
retrieval -->|guides| few_shot
few_shot -->|informs| MA
MA -->|retrieves| task_state
Can Language Models Teach Weaker Agents? Teacher Explanations Improve Students via Theory of Mind
In this work, the Theory of Mind (ToM) concept is used to attempt to improve the performance of students. Github
Generative Agents: Interactive Simulacra of Human Behavior in a simulated town!!!
This paper discusses a simulation involving different agents exhibiting different personalities. The dynamic environment, shared in code can be manipulated by these agents. The paper explores various challenges and proposed solutions including:
**Remembering**
_Observation Memory_ This is a memory stream that maintains a record of past experiences. These experiences are stored in "memory objects", which are described in natural language, and timestamped. The importance of each memory object is determined using metrics such as _recency_, _importance_, and _relevance_.
_Reflection Memory_ This memory type allows the agent to generate more abstract thoughts. These thoughts can be included along with reflections. This process is hardcoded to occur when the sum of importance scores exceeds a certain threshold.
**Planning and Reacting**
_Recursive Planning_ In this process, the agent divides the day into chunks of "goals", which are further broken down into smaller time frames. The ability to adjust these plans based on interactions is a key feature of this mechanism.
Multi-Agent Collaboration via Reward Attribution Decomposition
This work illuminates optimization techniques for multi-agents using distributed reward systems to achieve state-of-the-art performance. It introduces a joint optimization approach that depends on self and interactive terms.
Super-AGI is a model that allows multiple agents to function. However, this system doesn't facilitate any communication between the agents.
This model applies several iterations to improve negotiation tactics based on external feedback.
RL4L AI employs a small critique model to enhance the output from the larger model. It uses a policy gradient to fine-tune the critique model while maintaining reasonable performance gains. Github
Showrunner Agents The Showrunner Agents use Large Language Models (LLMs) to generate episodic content.
It's a massively creative and multi-faceted process with a great potential.
Improving Factuality and Reasoning in Language Models through Multiagent Debate where multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer.
They tried both concatenation or summarization of other results. Summarization reduces length and improves quality.
# Debate Length Prompt
short_prompt = """ These are the solutions to the problem from other agents: {other_answers}
Based off the opinion of other agents, can you give an updated response . . ."""
long_prompt = """ These are the solutions to the problem from other agents: {other_answers}
Using the opinion of other agents as additional advice, can you give an updated response . . ."""
 Council Very promising initial creation of networks of agents to create full-fledged teams for output products.
Council Very promising initial creation of networks of agents to create full-fledged teams for output products.

SocraticAI to use the power of conversation to solve problems. Very interesting
MAgICoRe: A Multi-Agent Coarse-to-Fine Refinement Framework for Reasoning
The authors show int heir paper a quality multi-agent system enabling a 'solver, reviewer and 'refiner to enable improved solutions, improving performanceabove other methods.
Swarms¶
 Heirarchichal Autonomous Agent Swarm: HAAS to create self-direct, self-correcting, and self-improving agent systems.
Heirarchichal Autonomous Agent Swarm: HAAS to create self-direct, self-correcting, and self-improving agent systems.
Very thoughtful next-level systems focusing on large-dimensions of swarms. Very initial stages but has a lot of promise. Github
Potentially useful tools¶
Nomadproject.io A simple and flexible scheduler and orchestrator to deploy and manage containers and non-containerized applications across on-prem and clouds at scale.
Firecracker 'Our mission is to enable secure, multi-tenant, minimal-overhead execution of container and function workloads.'